
ChatGPT update enables all GPT-4 tools simultaneously

Reviewed By: Kevin Pocock

Table of Contents
The all tools update to OpenAI’s AI chatbot ChatGPT lets users use all of this years new features at the same time. These features, which are only available for GPT-4, include Browse with Bing, Advanced Data Analysis, Plugins, and DALL·E 3. This represents a significant step towards a multimodal user experience, combining more generative AI tools than competitors Bing Chat or Google Bard.
ChatGPT “All Tools” update
The new ChatGPT update allows OpenAI’s AI chatbot to use all premium features at the same time.
Prime Day is finally here! Find all the biggest tech and PC deals below.
- Sapphire 11348-03-20G Pulse AMD Radeon™ RX 9070 XT Was $779 Now $739
- AMD Ryzen 7 7800X3D 8-Core, 16-Thread Desktop Processor Was $449 Now $341
- ASUS RTX™ 5060 OC Edition Graphics Card Was $379 Now $339
- LG 77-Inch Class OLED evo AI 4K C5 Series Smart TV Was $3,696 Now $2,796
- Intel® Core™ i7-14700K New Gaming Desktop Was $320.99 Now $274
- Lexar 2TB NM1090 w/HeatSink SSD PCIe Gen5x4 NVMe M.2 Was $281.97 Now $214.98
- Apple Watch Series 10 GPS + Cellular 42mm case Smartwatch Was $499.99 Now $379.99
- ASUS ROG Strix G16 (2025) 16" FHD, RTX 5060 gaming laptop Was $1,499.99 Now $1,274.99
- Apple iPad mini (A17 Pro): Apple Intelligence Was $499.99 Now $379.99
*Prices and savings subject to change. Click through to get the current prices.
No official announcement has been made yet on social media, or via the OpenAI blog. However, users are starting to see a notification when accessing ChatGPT that reads:
- Upload many types of documents: Work with PDFs, data files, or any document you want to analyze. Just upload and start asking questions.
- Use Tools without switching: Access to Browsing, Advanced Data Analysis, and DALL·E is now automatic. (if preferred, manual selection is still available under GPT-4.)
Essential AI Tools
What is a VML?
In the same year that the world learned what an LLM (Large Language Model) was, the technology was usurped by the VLM, or Visual Language Model. A VLM is a neural network that has been trained on text-image pairs in addition to the text-based training data of an LLM.
GPT-4V is great for content creation because you can generate unique images for social media. AI capabilities relating to content generation will skyrocket this year, with photorealistic video expected by 2025, and AI-generated audio is pretty much already there.
As a result, a VLM can accept a visual input, and uniquely perform the following tasks:
Visual Captioning (VC)
A unique emergent ability of image recognition technology. Very similar to Visual Question Answering (VQA), to the point that you can expect to find a 100% correlation of VQA and VC being present in a VLM, this generates descriptions of a visual input. It is essentially image recognition in its purest form, translated for humans, allowing us to read what the AI system thinks it can see.
Visual Commonsense Reasoning (VCR)
Beyond a description of the image itself and its contents, VCR is an observant analysis of an image, the kind that you might expect when showing it to another human without prompting them to respond in any specific way. In the same way, if you submit and image to a VLM with no text prompt, it will decide what you should know about it on your behalf. This will be based on what others have asked about images, weighted towards images of a similar nature. For example, a VLM may take the initiative to tell you the name of the individual when presented with an input image of a human face. By contrast, commonsense reasoning would tell it not to respond in the same way to an image of a clock face.
Multimodal Affective Computing (MAC)
Visual affective information is a field of study defining how a visual stimuli would make a human feel (or affect their psychology, more broadly speaking). Due to the emotional context of an image not being an inherent property of an image, this would be impossible to interpret by any direct or objective computation. Instead, a computer can be trained on image-response data pairs, which at the computational level means data that can be collected by an electrocardiogram (ECG), pulse rate (PR) monitor, and by a humans galvanic skin response (GSR). The merging of psychology and machine learning is extremely advanced, even by comparison to other subsets of ML technology, not least because of the specialist hardware required to develop a usable dataset.
Natural Language for Visual Reasoning (NLVR)
NLVR pairs natural language processing (NLP) with text-image pairs to determine the accuracy of a statement about an image. Conceptually similar to fact-checking, but of course facts relating to current events will require internet access (possible with ChatGPT).
Visual Retrieval (VR)
The ability of an AI system to find an image for you, based on a textual description. Aside from local system search, this functionality also requires internet accessibility, which isn’t an inherent ability of a VLM. However, ChatGPT does have internet access, meaning that the ‘All Tools’ update allows ChatGPT to retrieve images based only on a textual description.
Vision-Language Navigation (VLN)
The ability of an AI system to navigate a physical space by textual description (or verbal instruction using speech-to-text translation). This is the study of how humans and robots can communicate in natural language, perceive an environment, and perform real-world tasks. It includes not only locomotion and spatial awareness, but also identification and interaction with objects in that space.
Multimodal Machine Translation (MMT)
Generative summation of multiple data sources of different modalities. Artificial intelligence can take both a textual statement about an image, as well as the image in question, and output a a new statement that takes both inputs into account. The translation refers to that of different modalities of media (i.e. text, image, audio, and video) as opposed to human language translation. However, modern AI systems can also do this in the same breath.
Visual Question Answering (VQA)
The capability for an AI system to respond intelligently to a visual input. This means cognition of the content and or context of the image through image recognition, not simply responding to the presence or metadata of an image, which can be done without image recognition. A visual input can be an image or a video in theory. However, ChatGPT doesn’t accept video inputs yet.
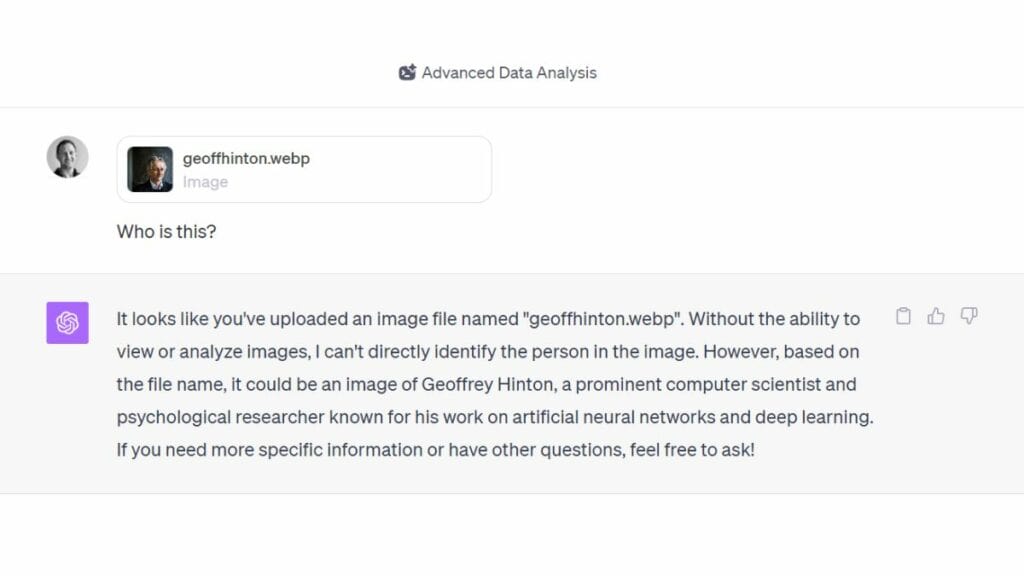
How to access the ChatGPT VLM
To access the VLM functionality of GPT-4V, you’ll need to be a paying ChatGPT Plus subscriber. You can also make use of VLM model via the OpenAI API. The free version of ChatGPT cannot do any of the cool things mentioned in this article. However, you can create image captions, blog posts, ads, and template/outlines for other forms of content with GPT-3.5. GPT-4 features such as ChatGPT plugins make it the more powerful tool, but the free version is extremely capable for text-based queries and outputs.
About the Author